Example project using the Exa Python SDK
Click here to try Exa-powered Twitter Retrieval
What this doc covers
-
Creating an alternative way to retrieve tweets powered by Exa by searching our index (updated daily)
-
Explain usage of Exa's includeDomain and date filters
If you're interested in searching for and retrieving Tweets, Exa can be a great way to do this semantically. X is included in our indexing and we are constantly crawling to keep public data fresh.
Why search for tweets?
- Read about your favorite topic or domain in a synthesized/targeted way
- Get notified about new hackathons/events (often primarily announced via Twitter)
- Monitor feedback/user experiences for your product
In this quick tutorial, we'll use Exa to retrieve relevant X posts using the includeDomain parameter to filter to Twitter.com/X.com content only. The Jupyter notebook for this tutorial is available on Colab for easy experimentation.
To play with this code, we just need a Exa API key
Let's start by installing the Exa Python SDK, importing the required libraries, and instantiating the Exa client.
!pip install exa_py # install the Exa Python SDK
from google.colab import userdata # comment this out if you're not using Colab
from exa_py import Exa
import os
from datetime import datetime, timedelta
import requests
from IPython.display import HTML, display
EXA_API_KEY = userdata.get('EXA_API_KEY') # replace userdata.get(...) with your API key, or add your API key to Colab Secrets
exa = Exa(EXA_API_KEY)
Next, we're going to use Exa to pull tweets from Twitter/X based on any query. But first, let's define a helper function that renders tweets in Colab like you'd see them on Twitter (instead of plain text), for visualization purposes. You don't need to understand how this works.
def get_tweet_embed(tweet_url):
oembed_url = f"https://publish.twitter.com/oembed?url={tweet_url}&hide_thread=true"
response = requests.get(oembed_url)
if response.status_code == 200:
return response.json()['html']
else:
return None
Now, let's specify some parameters and call the Exa API.
We set include_domains so that Exa only searches Twitter.com and X.com URLs for results. We also set the start_published_date to thirty days before the current date. This way, we only get recent tweets.
And since things move so fast in AI, let's set our query to find advances in AI so we can catch up on news from the last month.
query = "here's an exciting breakthrough in artificial intelligence:"
include_domains = ["twitter.com", "x.com"]
num_results = 10
# Calculate the date for one week ago
one_month_ago = (datetime.now() - timedelta(days=30)).isoformat()
# Execute the search
search_response = exa.search_and_contents(
query,
include_domains=include_domains,
num_results=num_results,
use_autoprompt=True, # improves your query to work with Exa better
text=True,
start_published_date=one_month_ago
)
Now, let's put everything together.
results = search_response.results
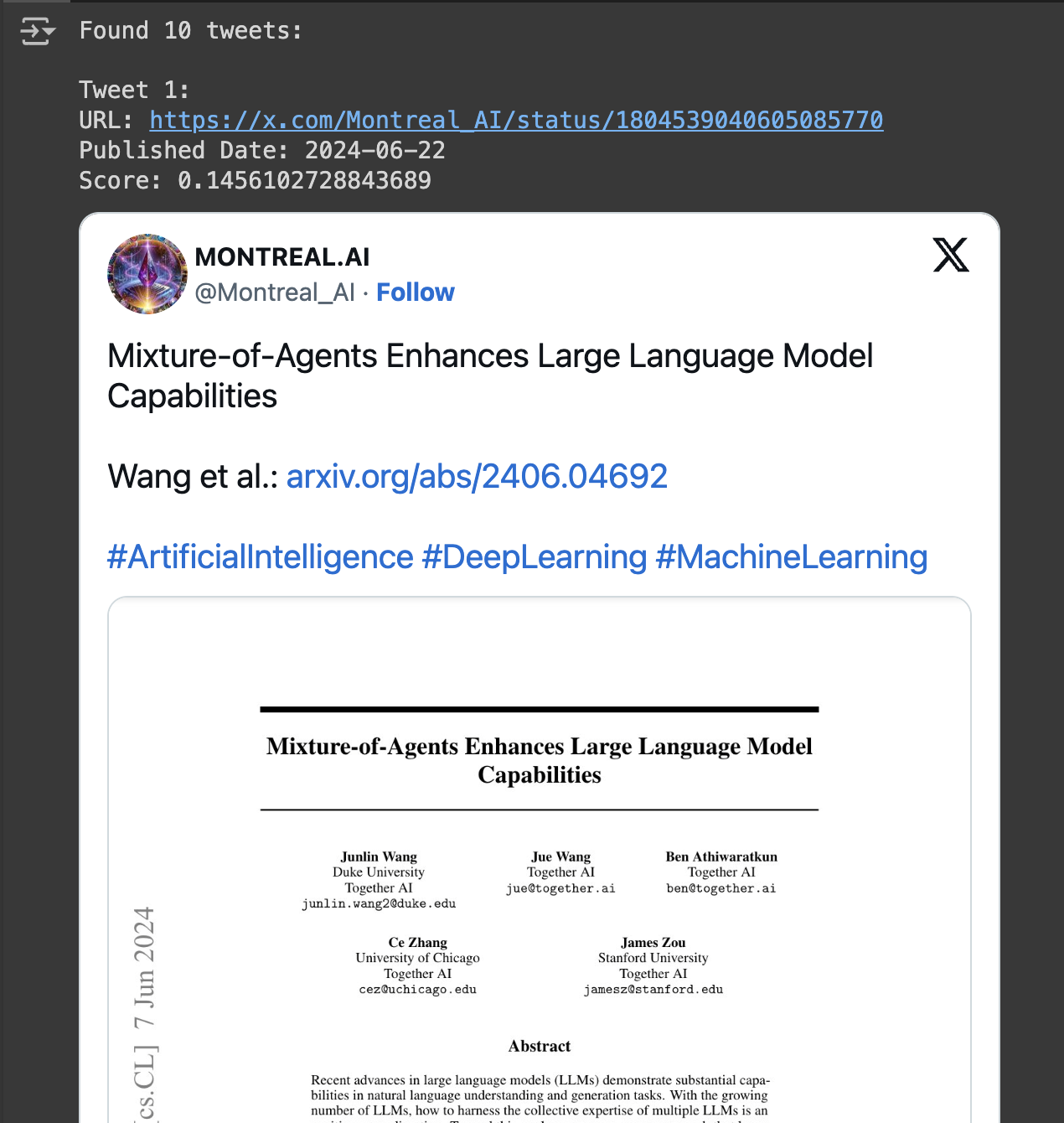
print(f"Found {len(results)} tweets:\n")
for i, result in enumerate(results, 1):
print(f"Tweet {i}:")
print(f"URL: {result.url}")
print(f"Published Date: {result.published_date}")
print(f"Score: {result.score}")
# Get and display tweet embed
embed_html = get_tweet_embed(result.url)
if embed_html:
display(HTML(embed_html))
else:
print("Sorry, unable to load tweet embed.")
print("\n" + "-"*50 + "\n")
print("That's all, folks!")
You should see the actual tweets appearing right in your Colab output! Notice that Exa also provides a relevance score (from 0 to 1), indicating how well the retrieved content matches your query. A low score doesn't necessary mean something is irrelevant but you may want to keep an eye on relevance scores, especially if you are requesting a lot of results. Similarly, if you Google something and go to the fiftieth result, that's going to be less relevant than the first result.
Besides Twitter/X, Exa also indexes YouTube (and many other sites, see detailed info about what's in our index here ). As a follow-up, experiment with setting includeDomain to "youtube.com" to find cool videos to binge!